Differential Privacy
As an academic researcher and a security professional, I have mixed feelings about Apple’s announcement. On the one hand, as a researcher I understand how exciting it is to see research technology actually deployed in the field. And Apple has a very big field.
On the flipside, as security professionals it’s our job to be skeptical — to at a minimum demand people release their security-critical code (as Google did with RAPPOR), or at least to be straightforward about what it is they’re deploying. If Apple is going to collect significant amounts of new data from the devices that we depend on so much, we should really make sure they’re doing it right — rather than cheering them for Using Such Cool Ideas. (I made this mistake already once, and I still feel dumb about it.)
But maybe this is all too „inside baseball“. At the end of the day, it sure looks like Apple is honestly trying to do something to improve user privacy, and given the alternatives, maybe that’s more important than anything else.
Matthew Green, Krypto-Professor an der John Hopkins Universität in Baltimore, schreibt den Artikel, den jeder zum Thema gelesen haben sollte.
Der Knackpunkt von Differential Privacy ist ein Parameter der sich „privacy budget“ nennt. Wie viel „Rauschen“ (falsche Werte) streue ich in eine Erhebung von Daten ein um individuelle Nutzer nicht zu identifizieren, gleichzeitig aber auch nicht die Untersuchung zu verfälschen.
Differential Privacy, Apples Verwendung eines Models, das in der Wissenschaft bei einer statistischen Analyse eingesetzt wird, ist in der Theorie simpel, aber in der Umsetzung schwierig. So schwierig, dass einige Studien dieses Modell für „eingeschränkt praktikabel“ erachten.
Ein Projekt, das Differential Privacy bereits mit großem Datensatz betreibt, tatsächlich betreibt, ist Google. Das Team aus Mountain View lernt mit einer (vermeintlich) ähnlichen Implementierung wie weit verbreitet unter Chrome-Nutzern Schadsoftware ist, die deren Browser-Einstellungen (ungewollt) hijacken.
To understand RAPPOR, consider the following example. Let’s say you wanted to count how many of your online friends were dogs, while respecting the maxim that, on the Internet, nobody should know you’re a dog. To do this, you could ask each friend to answer the question “Are you a dog?” in the following way. Each friend should flip a coin in secret, and answer the question truthfully if the coin came up heads; but, if the coin came up tails, that friend should always say “Yes” regardless. Then you could get a good estimate of the true count from the greater-than-half fraction of your friends that answered “Yes”. However, you still wouldn’t know which of your friends was a dog: each answer “Yes” would most likely be due to that friend’s coin flip coming up tails.
„Learning statistics with privacy, aided by the flip of a coin“
Der Aufwand ist notwendig, weil die zusätzlich eingefangenen Daten der Anonymisierung entgegenlaufen. Es reicht nicht aus einfach nur den Namen oder die ID aus dem Datensatz zu löschen.
And part of the reason that this is so important to get into is because, the theory that you can just anonymize the data and send it up, and all’s good, and it’s a bunch of crap —
Because I can send all this data, and say „Well, I don’t know who you are, oh, but I happen to know the same location you go to every night, and I know the same place you go to work every day, I’ve got all this data, I just don’t know your name, or ID. Boy, it’s really hard to reverse-engineer that anonymous data!“
Right? So what you need to do is create a system that goes beyond anonymizing to really make it impossible to reconfigure who that user is.
Apples selbsterklärtes Ziel ist es, dass erst gar kein Datensatz entsteht, bei dem die Chance einer Metadaten-Auswertung bestünde (auch nicht in der Zukunft):
(…) the point of view that someone says, „Hey, I know we know a ton about you, but don’t worry! We’re nice guys! And it’s all good!“
Well, okay, maybe you’re nice guys, ten years from now, who’s running this thing? Or, what if someone breaks into your computers? Are they nice guys?

Differential Privacy ist damit ein selbst auferlegter Kompromiss – ein Kompromiss zwischen Datenschutz der teilnehmenden Nutzer_innen und einer Genauigkeit der erhobenen Werte.
Es ist sehr einfach (anonymisierte) Rohdaten zu sammeln, auszuwerten und damit seine Algorithmen und Modell zu trainieren. Dies jedoch in einer Form zu tun, die mathematisch allen Teilnehmern und Teilnehmerinnen Anonymität garantiert (und nicht nur die Spalte mit den dazugehörigen Namen löscht), ist ein hehres Ziel. Ein hehres Ziel dessen Erfolg sich ‚von Außen‘ – ohne extra Informationen von Apple – schwierig überprüfen lässt.
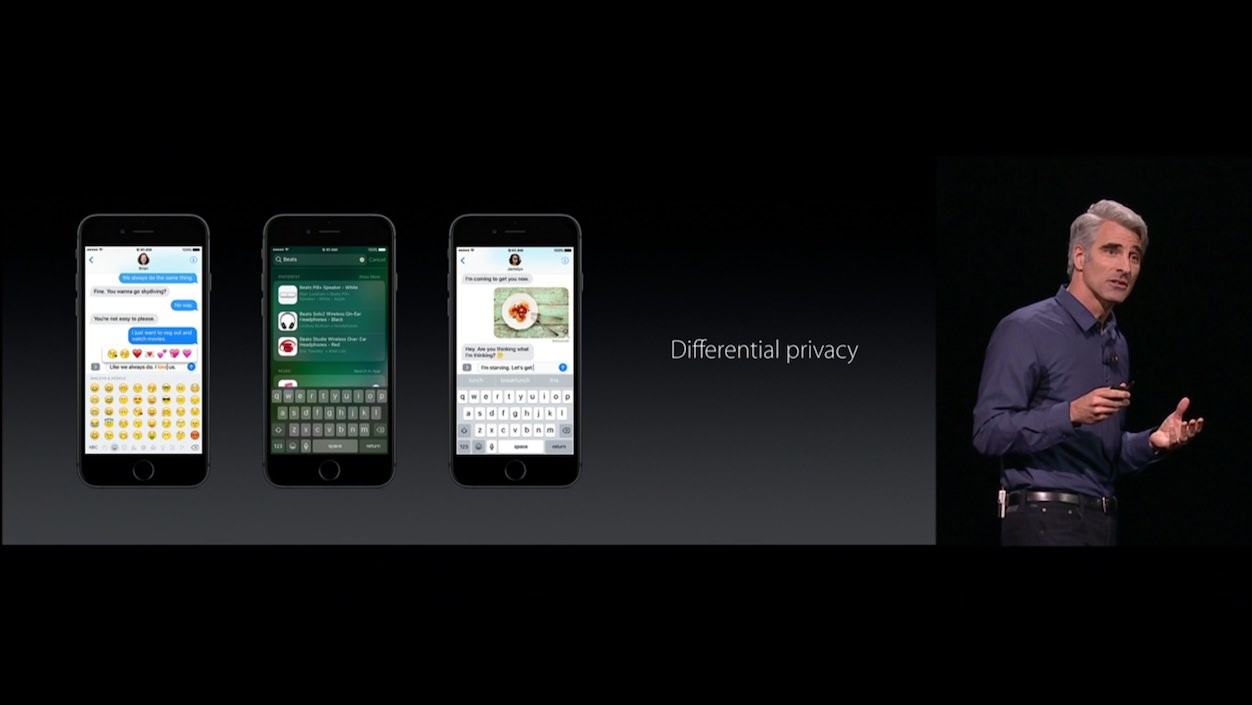
Vielleicht bekomme ich eine Taco-Emoji-Empfehlung auf der QuickType-Tastatur weil jeder das kleine Bildchen durch die Gegend schickt. Vielleicht taucht der Vorschlag aber auch nur auf, weil der künstlich verwässerte Datensatz zu ungenau ist.
Trotz alledem stehen diese (noch) offenen Fragen in keinem Vergleich mit der Art und Weise wie Google, Facebook oder Amazon Nutzerdaten sammeln und auswerten. Das ist nicht zwangsläufig eine Wertung, sondern aus technischer Perspektive lediglich ein anderer Kompromiss (der die einfache Frage nach sich zieht ob die von Apple gewonnen Ergebnisse gut genug sind).